
Lower Rank Adaptation (LoRA): A Leap Towards the Democratization of Large Language Models

Recent advancements in large language models (LLMs) have stirred considerable excitement among researchers and the broader public. However, the vast computational resources required for these models have been a significant barrier, inhibiting the broad usage of these tools. While LLMs are highly sophisticated, both the training and inference stages demand extensive GPU compute resources, making them less accessible for the general public. This accessibility issue is particularly problematic for models fine-tuned for specific downstream tasks – a crucial function for users who rely on tools like ChatGPT in specialized fields.
Nevertheless, new research is being conducted to mitigate these computational challenges. In this post, we will delve into one such method known as Lower Rank Adaptation (LoRA), introduced by Hu et al.
The Simplicity of LoRA
On the surface, the concept behind LoRA is quite simple. For instance, if we consider a model with 7 billion parameters - a size now deemed relatively "small" in the world of LLMs - LoRA suggests that we need not fine-tune all parameters. Instead, the method operates under the assumption that the desired model state can be reached by modifying a much smaller number of parameters.
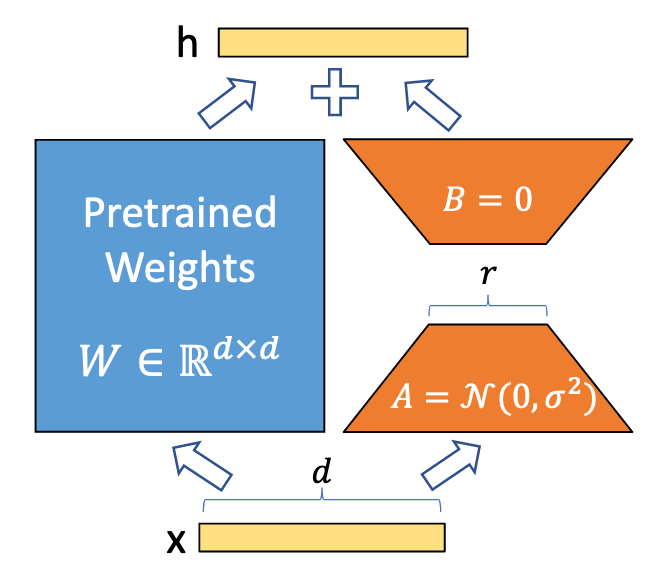
In detail, LoRA employs a lower-rank projection matrix to adapt the high-rank parameters. This essentially means that instead of changing the entire parameter space, it selectively modifies a lower-rank subspace. While the original parameters remain static, the projected lower-rank matrix adapts to the specific task. This dramatically reduces the computational burden while allowing the model to specialize effectively.
By modifying only a subset of the parameters, LoRA essentially condenses the complex, multi-billion-parameter model into a much more manageable form. This approach provides a balance between maintaining the power of large pre-trained models and enabling efficient fine-tuning.
Recent Advancements with LoRA
Recently, a new technique that expands on LoRA, known as Quantized Lower Rank Adaptation (QLoRA), has shown to achieve the best performance among open-source language models - Guanaco. This enhancement of the LoRA technique emphasizes its potential in fine-tuning LLMs effectively, further democratizing access to these sophisticated tools.
The strides made by techniques like LoRA and QLoRA are undeniably significant, taking us a step closer towards a future where LLMs are more accessible. These methods are beginning to bridge the gap between the vast computational requirements of LLMs and the limited resources available to the majority of users, shedding light on a promising path towards the democratization of AI technology.
Despite these advancements, there is still much work to be done. As the field of AI continues to grow and evolve, so must our efforts to make these powerful tools more accessible. LoRA and its successor QLoRA, serve as testament to the ingenuity of AI researchers worldwide and a beacon of hope for a future where everyone can harness the power of large language models.