
Overcoming Context Window Length Limitations in Transformer Architectures

GOAT AI RESEARCH LAB
As the field of AI continues to advance, large foundational models like ChatGPT and GPT-4 have captured the interest of diverse professionals. However, an ongoing challenge in transformer architectures is the constraint imposed by the context window length. For instance, widely-used LLaMA models are limited to a 2048 token context window. This means that when responding to input, the model can only consider a maximum of 2048 "words." To address this issue, researchers have proposed various solutions, which we will explore in this article along with our own approach.
The Limitation of Context Window Length:
The context window length limitation poses a significant hurdle for transformers. If an input exceeds the specified length, crucial information may be disregarded during the model's response generation process. This has spurred numerous academic efforts to tackle the problem, aiming to expand the effective context window for improved performance.
Flash Attention - An Attempted Solution:
One well-known approach to address the context window length limitation is Flash Attention, proposed by Dao et al. This method attempts to increase the window length; however, it is not without its limitations. The scaling of this approach relies heavily on the VRAM of GPUs, thereby bottlenecking its performance improvement potential. Consequently, alternative solutions have been sought to overcome this challenge more effectively.
Inspiration from VectorDB Retrieval Methods:
Drawing inspiration from vectorDB retrieval methods, particularly the works of Borgeaud et al. and Lewis et al., which highlighted the impact of conditioning retrieved texts on LLMs (Language Models), our initial plan was to develop a model employing a similar logic to that of Rubin et al.'s self-retrieval approach.
The Power of RecurrentGPT:
Ultimately, our team arrived at a solution known as RecurrentGPT, introduced by Zhou et al. This approach draws parallels to Recurrent Neural Networks (RNNs) and emulates their functionality. By dividing prompts into outputs, short-term memory, long-term memory, and plans, RecurrentGPT enables the conditioning of subsequent output generations on previous short-term/long-term memories and plans. This recursive process empowers the model to generate texts of arbitrary length, effectively bypassing the limitations imposed by the context window length.
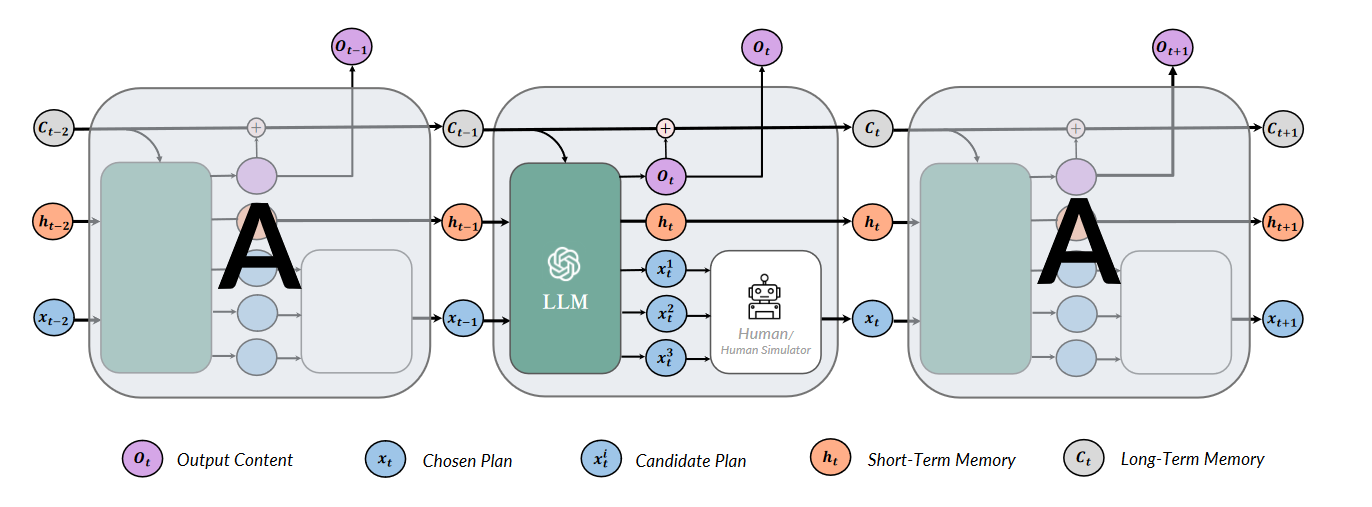
Conclusion:
Overcoming the context window length limitation in transformer architectures is crucial for the advancement of AI models. While Flash Attention has been a prominent attempt to tackle this challenge, its scalability remains dependent on GPU VRAM. Our approach, inspired by vectorDB retrieval methods and utilizing RecurrentGPT, offers a promising solution that circumvents the context window length limitation by simulating RNN-like behavior. By conditioning output generations on previous memories and plans, RecurrentGPT opens the door to generating coherent and concise texts of any desired length. As researchers continue to explore and refine solutions to this issue, the future of large foundational models holds exciting possibilities for AI applications in various domains.